Publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2026
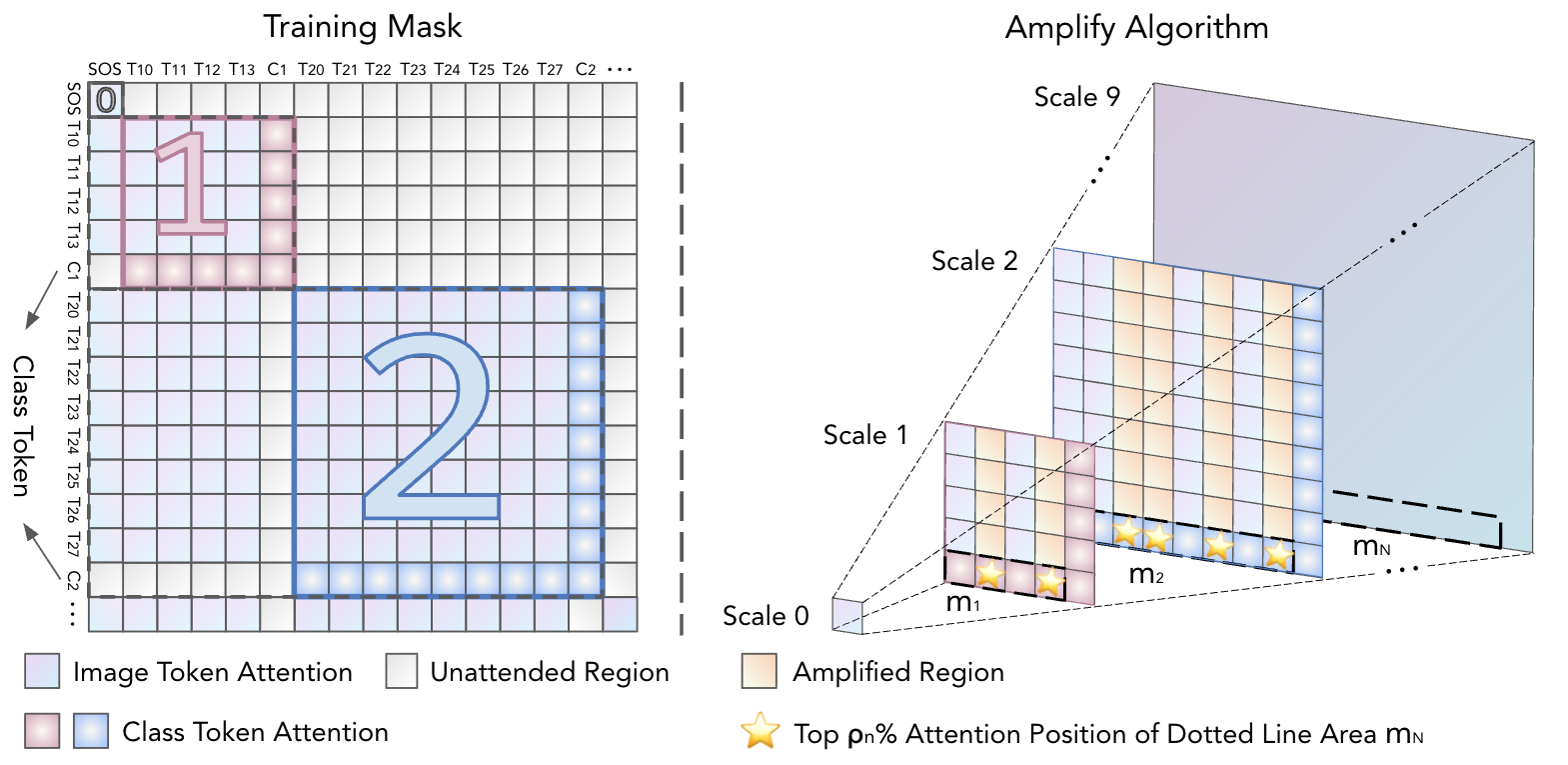
- HierAmp: Coarse-to-Fine Autoregressive Amplification for Generative Dataset DistillationXinru Jiang*, Lin Zhao*, Xi Xiao, and 7 more authorsIn The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2026, Jun 2026
Dataset distillation often prioritizes global semantic proximity when creating small surrogate datasets for original large-scale ones. However, object semantics are inherently hierarchical. For example, the position and appearance of a bird’s eyes are constrained by the outline of its head. Global proximity alone fails to capture how object-relevant structures at different levels support recognition. In this work, we investigate the contributions of hierarchical semantics to effective distilled data. We leverage the vision autoregressive (VAR) model whose coarse-to-fine generation mirrors this hierarchy and propose HierAmp to amplify semantics at different levels. At each VAR scale, we inject class tokens that dynamically identify salient regions and use their induced maps to guide amplification at that scale. This adds only marginal inference cost while steering synthesis toward discriminative parts and structures. Empirically, we find that semantic amplification leads to more diverse token choices in constructing coarse-scale object layouts. Conversely, at fine scales, the amplification concentrates token usage, increasing focus on object-related details. Across popular dataset distillation benchmarks, HierAmp consistently improves validation performance without explicitly optimizing global proximity, demonstrating the importance of semantic amplification for effective dataset distillation.
@inproceedings{zhao2026hierampcoarsetofineautoregressiveamplification, title = {HierAmp: Coarse-to-Fine Autoregressive Amplification for Generative Dataset Distillation}, author = {Jiang, Xinru and Zhao, Lin and Xiao, Xi and Fan, Qihui and Lu, Lei and Wang, Yanzhi and Lin, Xue and Camps, Octavia and Zhao, Pu and Gu, Jianyang}, booktitle = {The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2026}, month = jun, year = {2026}, }
2025
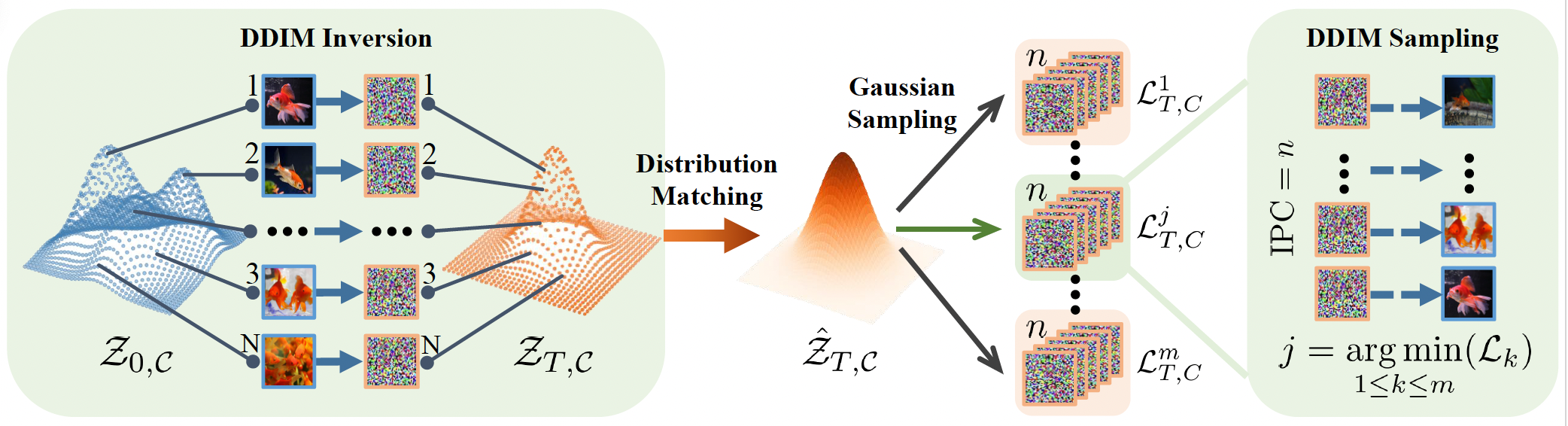
- Taming Diffusion for Dataset Distillation with High RepresentativenessLin Zhao, Yushu Wu, Xinru Jiang, and 5 more authorsIn Forty-second International Conference on Machine Learning, May 2025
Recent deep learning models demand larger datasets, driving the need for dataset distillation to create compact, cost-efficient datasets while maintaining performance. Due to the powerful image generation capability of diffusion, it has been introduced to this field for generating distilled images. In this paper, we systematically investigate issues present in current diffusion-based dataset distillation methods, including inaccurate distribution matching, distribution deviation with random noise, and separate sampling. Building on this, we propose D3HR, a novel diffusion-based framework to generate distilled datasets with high representativeness. Specifically, we adopt DDIM inversion to map the latents of the full dataset from a low-normality latent domain to a high-normality Gaussian domain, preserving information and ensuring structural consistency to generate representative latents for the distilled dataset. Furthermore, we propose an efficient sampling scheme to better align the representative latents with the high-normality Gaussian distribution. Our comprehensive experiments demonstrate that D3HR can achieve higher accuracy across different model architectures compared with state-of-the-art baselines in dataset distillation.
@inproceedings{zhao2025taming, title = {Taming Diffusion for Dataset Distillation with High Representativeness}, author = {Zhao, Lin and Wu, Yushu and Jiang, Xinru and Gu, Jianyang and Wang, Yanzhi and Xu, Xiaolin and Zhao, Pu and Lin, Xue}, booktitle = {Forty-second International Conference on Machine Learning}, month = may, year = {2025}, }
2024
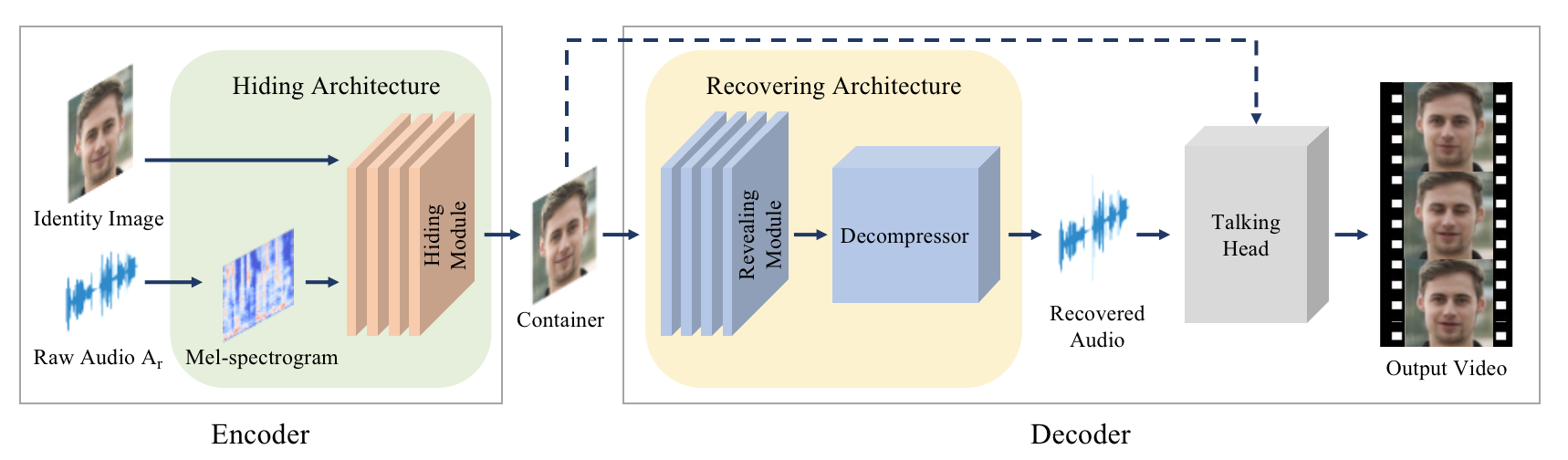
- THInImg: Cross-Modal Steganography for Presenting Talking Heads in ImagesLin Zhao, Hongxuan Li, Xuefei Ning, and 1 more authorIn Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Jan 2024
Cross-modal Steganography is the practice of concealing secret signals in publicly available cover signals (distinct from the modality of the secret signals) unobtrusively. While previous approaches primarily concentrated on concealing a relatively small amount of information, we propose THInImg, which manages to hide lengthy audio data (and subsequently decode talking head video) inside an identity image by leveraging the properties of human face, which can be effectively utilized for covert communication, transmission and copyright protection. THInImg consists of two parts: the encoder and decoder. Inside the encoder-decoder pipeline, we introduce a novel architecture that substantially increase the capacity of hiding audio in images. Moreover, our framework can be extended to iteratively hide multiple audio clips into an identity image, offering multiple levels of control over permissions. We conduct extensive experiments to prove the effectiveness of our method, demonstrating that THInImg can present up to 80 seconds of high quality talking-head video (including audio) in an identity image with 160x160 resolution.
@inproceedings{Zhao_2024_WACV, author = {Zhao, Lin and Li, Hongxuan and Ning, Xuefei and Jiang, Xinru}, title = {THInImg: Cross-Modal Steganography for Presenting Talking Heads in Images}, booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)}, month = jan, year = {2024}, pages = {5553-5562}, }